Analisando o espaço
Umas das coisas mais geniais que o geoprocessamento oferece é o poder de cruzar muitas informações geográficas. Esse “cruzamento” só é possível porque as informações compartilham algo em comum: o espaço.
Experimente empilhar camadas vetoriais de ruas, rios, bairros, topografia, cobertura do solo. Você verá os níveis de informação se acumulando na tela, compondo um emaranhado de feições que incrivelmente explicam como é a superfície da Terra. A partir daí é possível fazer perguntas para a massaroca de informações. E obter respostas.
Por exemplo, imagine que a prefeitura de um município quer descobrir quais locais são mais aptos para receber um projeto de habitação popular. Nesse exemplo ingênuo, em vez de simplesmente consultar os preços dos imóveis, os gestores realmente estão preocupados em identificar os melhores locais em função de critérios que indicam um bom estado de serviços públicos: ensino, saúde, lazer e mobilidade.
Os gestores decidem que tais serviços públicos são bem indicados pela proximidade a:
- Escolas públicas de ensino fundamental;
- Unidades básicas de saúde;
- Praças e parques, e;
- Avenidas troncais e coletoras.
Com as camadas vetoriais de tais informações, obtemos algo parecido com isso:
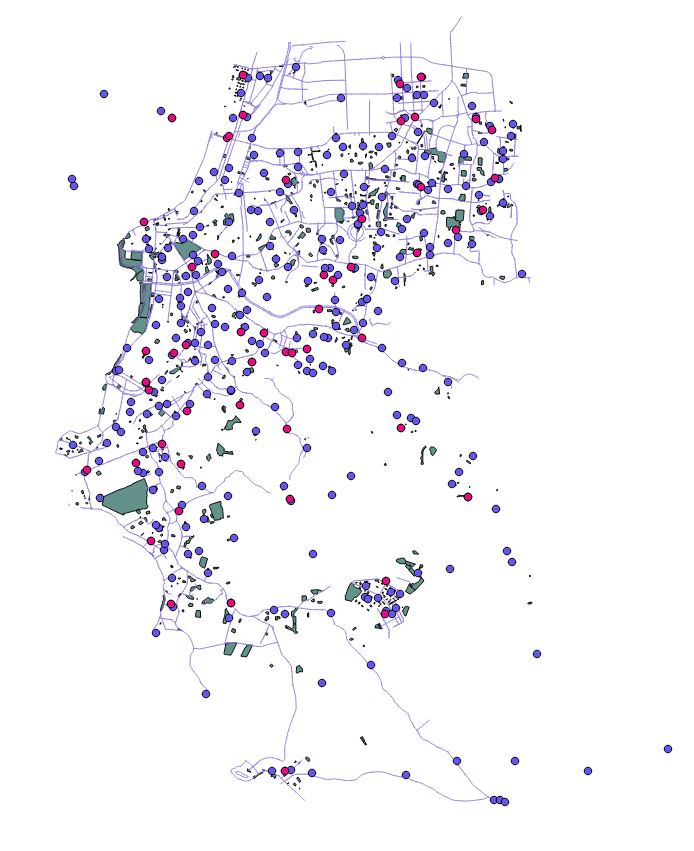
E agora? Como definir os melhores lugares?
Abordagem booleana
Uma forma de fazer a análise é definir limiares de distância aceitáveis para cada camada. No QGIS, isso significa gerar dilatações (buffer) com distância fixa as camadas. Por exemplo, suponha que a distância máxima aceitável para escolas é de 600 metros, das unidades de saúde, 2000 mil metros, das praças, 500 metros, e das avenidas, 300 metros.
Com as dilatações feitas, agora é só obter a intersecção entre elas. Isso significa fazer cortes (clip) em sequência. O resultado será uma camada vetorial que parecerá um colcha de retalhos que atende todas as distâncias aos indicadores.
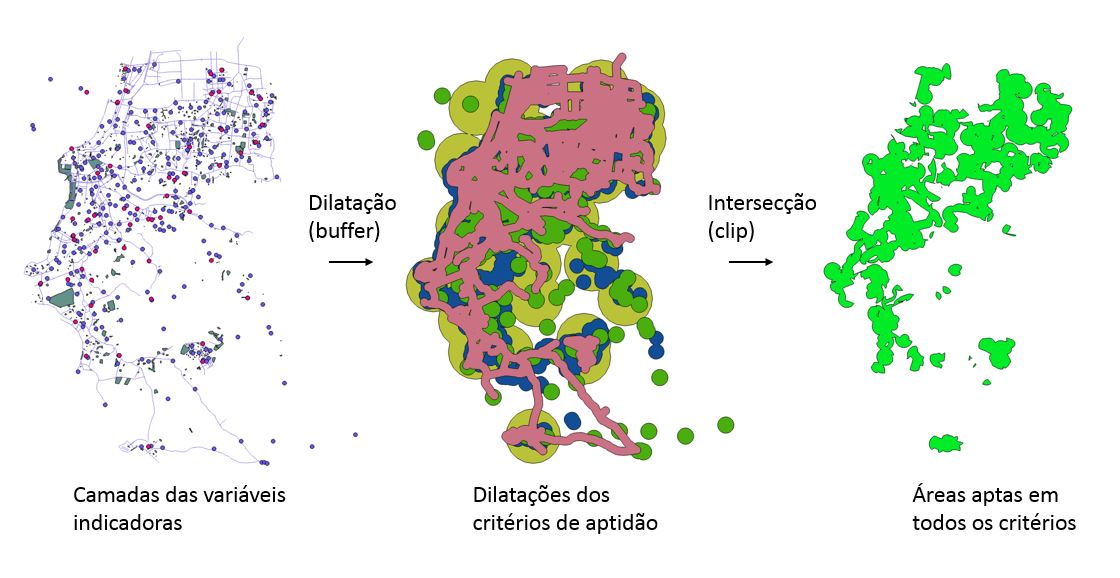
Essa abordagem vetorial é simples de realizar e só precisa da informação para as distâncias aceitáveis para cada camada. Uma reunião com especialistas nos respectivos assuntos resolve isso.
O problema é que essa abordagem responde apenas onde é apto e onde não é apto. Em suma, é uma análise booleana. Num problema mais realista, os gestores precisam avaliar muitas opções e possivelmente vão querer comparar as opções entre si. Com as contas públicas em jogo e as próximas eleições no horizonte, existem tradeoffs para serem avaliados. Imagine que essa abordagem deixe um terreno muito mais viável “fora do radar” por apenas 50 metros! Isso poderia ser usado pela oposição na audiência pública e ser um grande escândalo midiático.
Para tomar decisões econômicas e políticas mais seguras, os gestores do nosso problema imaginário precisam de um índice de aptidão para cada metro quadrado do município. Com esse índice, eles poderão avaliar a qualidade dos terrenos na confusão de sugestões dos acessores, movimentos sociais e lobistas da especulação imobiliária.
Abordagem fuzzy
Para compor um índice de aptidão para cada canto do município é preciso sair da lógica booleana e adentrar nos reinos da lógica fuzzy.
Na lógica booleana, não existem meias verdades. É ou não é. Ou é verdadeiro ou é falso. Em se tratando de variáveis espaciais, a lógica booleana prediz a posição de uma feição com 100% de certeza. Quando rasterizamos uma camada vetorial, geralmente obtemos uma imagem booleana com píxeis de 0 (onde é falso) e 1 (onde é verdadeiro). A “função de filiação” da lógica booleana é uma função discreta plana que apresenta discontinuidades entre o “verdadeiro” e o “falso”.
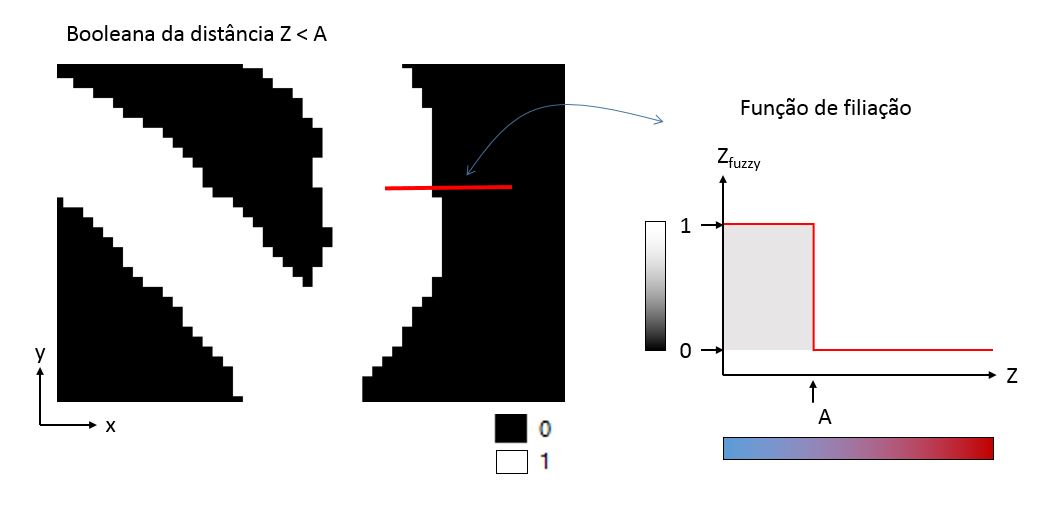
A lógica fuzzy antagoniza a lógica booleana. Na lógica fuzzy, as fronteiras das feições ficam “embaçadas”, “difusas” (por isso, fuzzy). A função de filiação na lógica fuzzy faz transições contínuas entre o verdadeiro e o falso, ou seja a imagem fuzzy apresenta píxeis que variam entre o zero e o um. São os cinquenta tons de cinza do geoprocessamento.
Mas voltando ao problema do indicador de aptidão, como sair da lógica booleana e ir para a lógica fuzzy?
“Fuzificando” a proximidade
Obviamente, precisamos abandonar as camadas vetoriais e partir para o mundo raster. Para isso, recomendo criar um novo campo numérico com o valor constante de 1 em cada camada das variáveis indicadoras. A seguir, crie (ou reuse) uma camada raster constante de valor zero. Faça cópias e renomeie as cópias com os nomes das variáveis indicadores. Rasterize sobre as camadas exisitentes (use a função rasterize over existing raster disponível no QGIS 2.18). Isso irá produzir imagens booleanas das variáveis indicadoras.
Refletindo um pouco, podemos perceber que a verdadeira variável indicadora que precisamos não é a existência ou não das feições como as escolas, praças e avenidas, mas a proximidade a essas feições. Assim, para cada imagem booleana, podemos criar um raster de proximidade (em: GDAL/OGR >> GDAL/Analysis >> Proximity (raster distance)).
Agora sim, em vez de estabelcer critérios duros de “bom/ruim” com base na proximidade, podemos bolar funções de filiação para fazer a transição das regiões plenamente boas para as regiões plenamente ruins. Com isso, teremos “fuzificado” a variável “proximidade” de acordo com nosso critério de aptidão.
Escolher a função de filiação pode ser a parte mais delicada do processo. As funções podem ser complexas e ter muitos parâmetros que em teoria precisam ser calibrados ou pelo menos verificados por opinião especialista. Considere a função de transição linear apresentada acima. Ainda que simples, ela possui dois parâmetros: a distância A, onde começa a transição linear, e a distância B, onde termina a transição.
Outra função simples é o decaimento exponencial. Essa função também precisa da definição de dois parâmetros: a distãncia A, onde o decaimento começa, e a distância T, onde o valor da função é 0.5 (meia vida do decaimento).
Para fuzificar a o raster de proximidade usando esses conceitos, você precisará abrir a calculadora raster a colocar a cabeça para funcionar. Mas se você prefir “colar”, no fim desse post eu apresento a fórmula para algumas funções mais úteis.
Obtendo o índice de aptidão global
Cada camada fuzzy gerada consiste em um índice de aptidão que varia de 0 a 1. Esses índices são relativos a cada variável indicadora. Para obter o índice de aptidão global uma alternativa é simplesmente fazer a média entre os índices. No nosso caso, somar e dividir por quatro.
Outras abordagens são válidas, como fazer uma média ponderada por pesos que vão impor mais importância de uma variável sobre as outras (por exemplo, a proximidade de escolas pode ter um peso superior ao restante). Se não houver consenso imediato ou a decisão for muito dura (como ocorre em outros tipos de projeto, como a alocação de aterros sanitários e presídios) pode-se inclusive pensar em vias participativas para a definição dos pesos.
O fluxograma geral do processo é seguinte:

Algumas funções de filiação
Fuzificar as variáveis espaciais pode ser um quebra-cabeça. Aqui vão alguns modelos simples de funções de filiação para serem usados na calculadora raster do QGIS. Não esqueça que o nome da camada e o valor dos parâmetros precisam ser manualmente alterados!
Transição linear
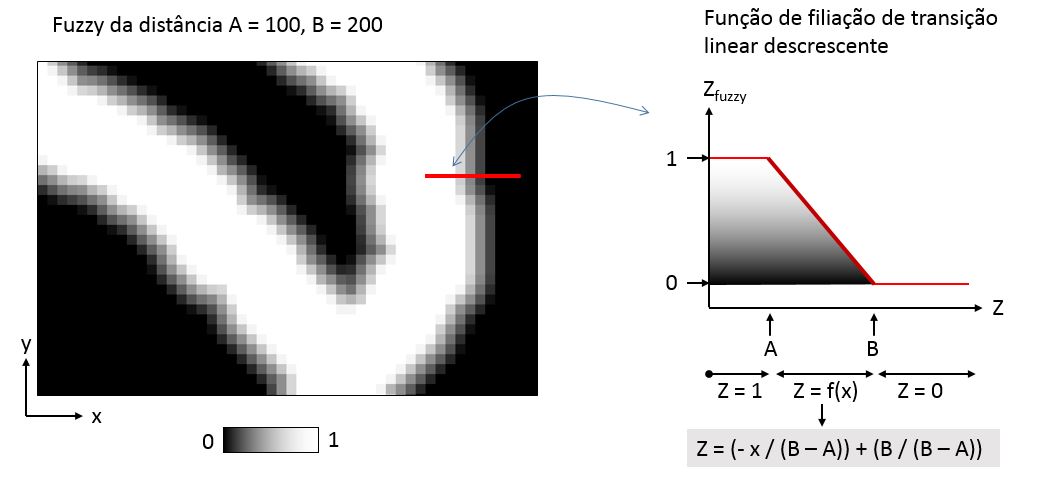
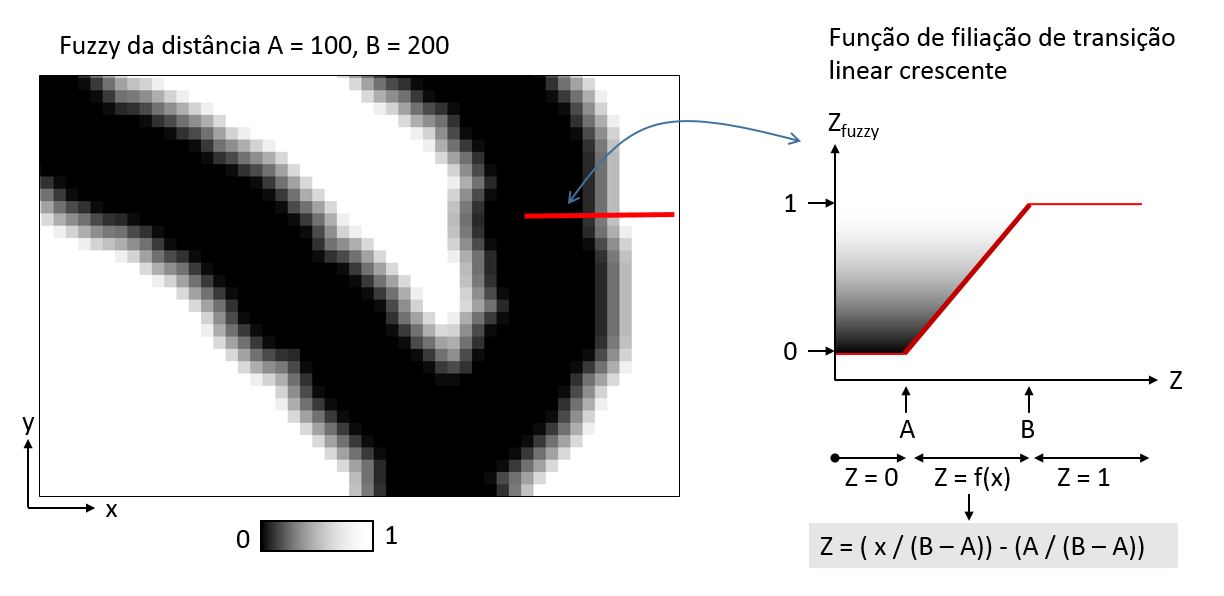
A transição linear é a mais simples. Ainda assim, é preciso definir os parâmetros A e B, onde a transição começa e termina, respectivamente. Se B for igual a A, voltamos para a lógica booleana.
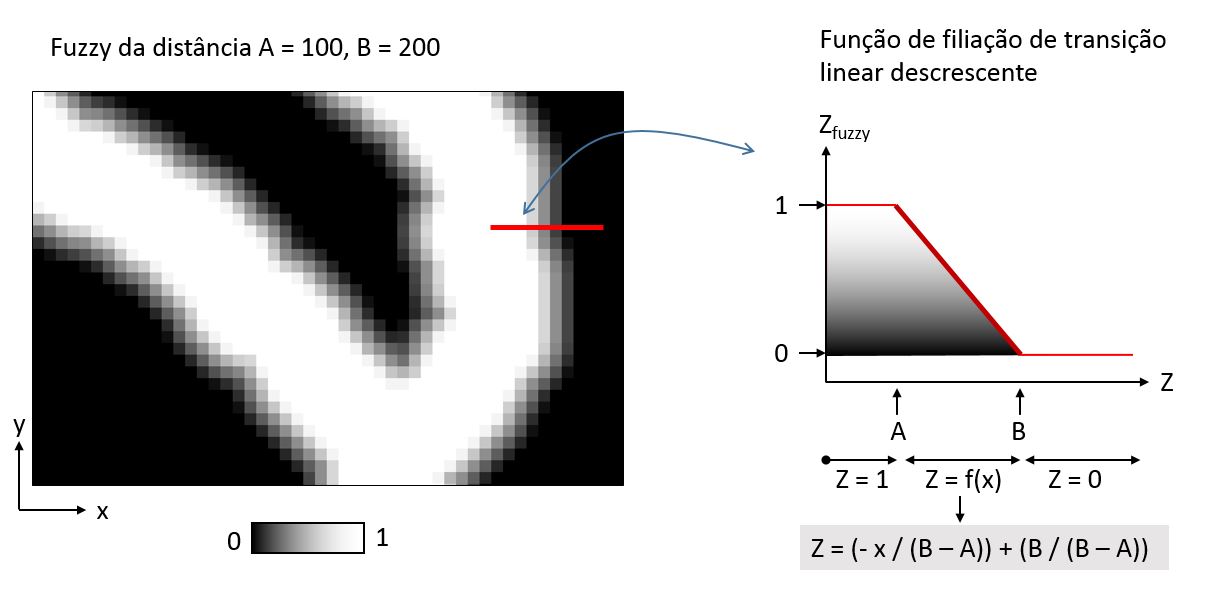
Fórmula para a transição linear descrescente:
(“proximidade@1” <= A) + (“proximidade@1” > A) * (“proximidade@1” < B) * ((- “proximidade@1” / (B – A)) + (B / (B – A)) )
Fórmula para a transição linear crescente:
(“proximidade@1” >= B) + (“proximidade@1” > A) * (“proximidade@1” < B) * (( “proximidade@1” / (B – A)) – (A / (B – A)))
Transição senoidal
Geralmente as transições com esse formato são definidos por funções sigmoides. Mas é possivel emular esse comportamento ao definir a função por partes e usando um termo senoidal. Os parâmetros A e B cumprem a mesma função da transição linear.
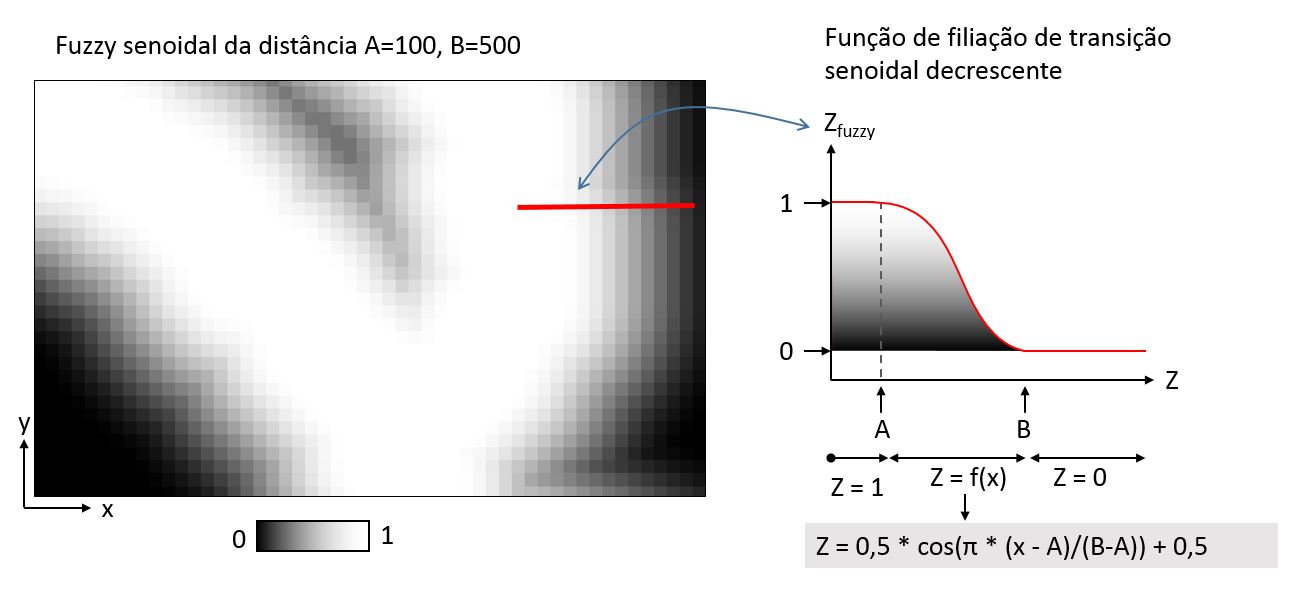
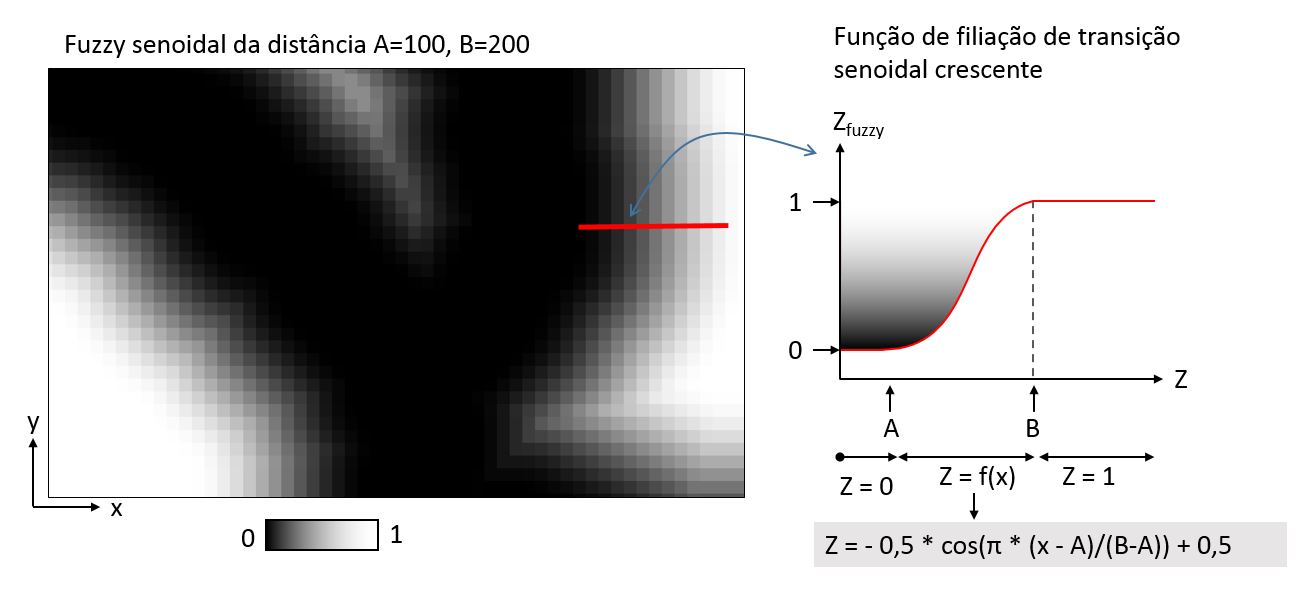
Fórmula para a transição senoidal descrescente:
(“proximidade@1” <= A) + (“proximidade@1” > A) * (“proximidade@1” < B) * (0.5 * cos(3.14159 * (“proximidade@1” – A)/(B-A)) + 0.5)
Fórmula para a transição senoidal crescente:
(“proximidade@1” >= B) + (“proximidade@1” > A) * (“proximidade@1” < B) * (-0.5 * cos(3.14159 * (“proximidade@1” – A)/(B-A)) + 0.5 )
Transição exponencial
A transição exponencial se aproxima assintoticamente de 0 ou 1. Isso quer dizer que o valor nunca será completamente atingido. O parâmetro T que dita o quão rápido acontece a aproximação é a meia-vida do decaimento exponencial (ou meia-distância, no nosso caso de variáveis espaciais). O parâmetro A define quando o limiar para a começar a transição.
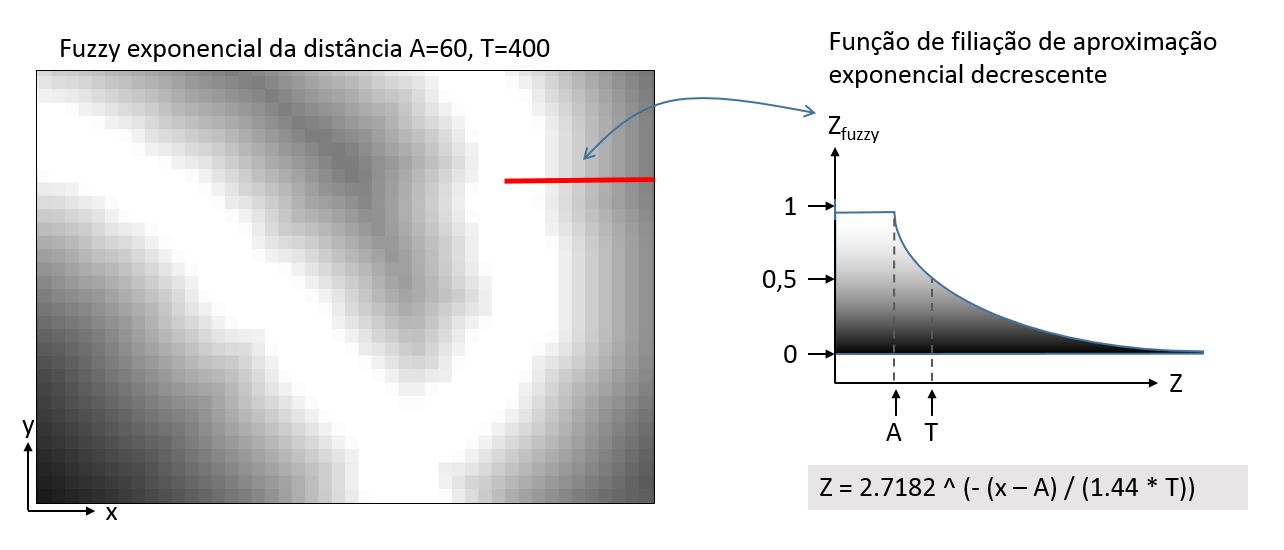

Fórmula para a transição exponencial descrescente:
(“prox_avenidas@1” <= A) + (“prox_avenidas@1” > A) * (2.7182 ^ (- (“prox_avenidas@1” – A) / (1.44 * T)))
Fórmula para a transição exponencial crescente:
(“prox_avenidas@1” > A) * (1 – (2.7182 ^ (- (“prox_avenidas@1” – A) / (1.44 * T))))
