
A Primeira Lei
Suponha que queiramos compreender algum fenômeno espacial específico em uma região, como o relevo, ou os solos, ou as rochas, ou a água subterrânea, ou o clima. Como não podemos, por falta de recursos (tempo e dinheiro), escrutinar cada milímetro quadrado da superfície e medir esse fenômeno, temos que agir de forma econômica: fazemos amostragens do fenômeno.
Da mais pura e simples coleta de campo aos produtos de sensoriamento remoto, estamos falando de amostragem. No caso das imagens amostradas por sensores, o píxel representa a unidade amostral, registrando o valor médio de radiação refletida por uma parcela finita do espaço. Essa parcela amostral pode ser grande o suficiente para esconder muitos objetos menores, como carros, pessoas, árvores.
Essa abordagem, felizmente, é resguardada pela Primeira Lei da Geografia, de Waldo Tobler:
“Todas as coisas estão relacionadas entre si, mas coisas próximas são mais relacionadas que coisas distantes.”
Isso quer dizer que é razoável assumir que as amostras que fazemos no espaço dizem bastante sobre seu entorno. Em termos mais rigorosos, quer dizer que a correlação espacial decai com a distância.
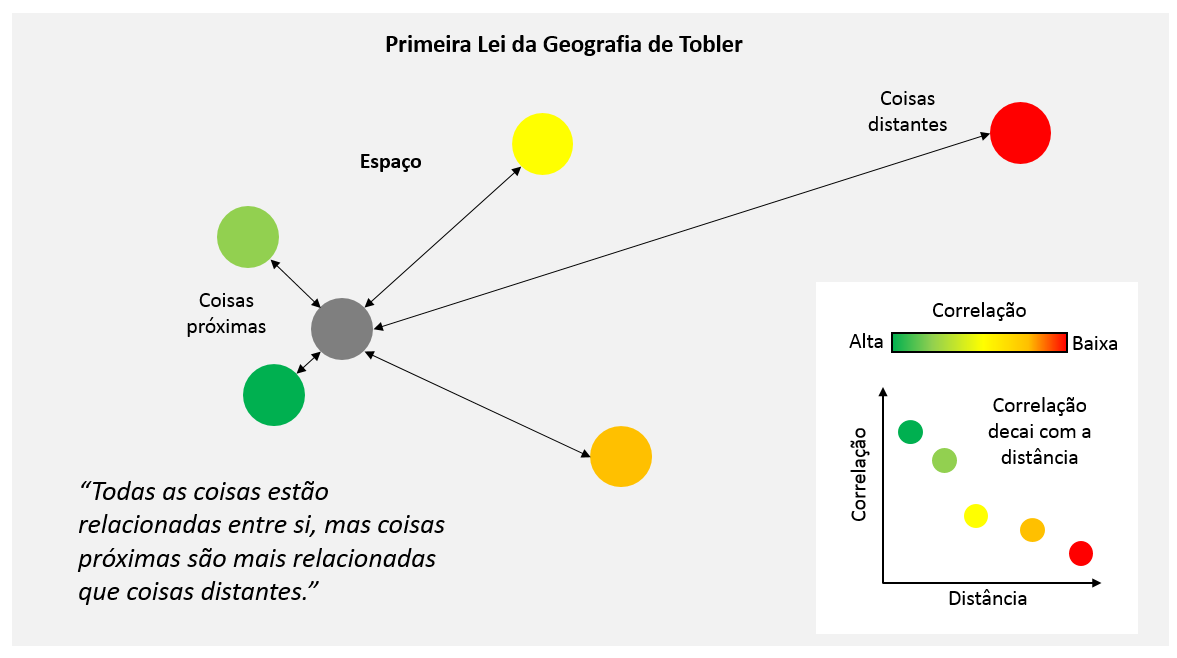
Se a análise de um píxel de uma imagem LandSat nos diz que ali é uma porção de floresta, quer dizer que provalemente a maior parte daquela parcela do espaço seja floresta. Mas nada impede que existam pequenas lagoas dentro da floresta. Além disso, podemos assumir que os píxeis contíguos também sejam floresta. O raciocínio é análogo para os Modelos Digitais de Elevação produzidos por sensores (como o SRTM).
Mas é fácil falar de amostragens extensivas e sistemáticas de sensores orbitais ou voadores (feitas em uma grade regular). E as amostragens simples, feitas por coletas? Pense na rede de pluviômetros que coleta a chuva incidente em pequenos pontos esparsamente distribuídos no espaço. Pense em poços de monitoramento de áreas contaminadas. Pense em sondagens geológicas e amostras de solo. Para esses casos, geralmente é infactível fazer amostragens sistemáticas em uma grade regular. Não há tempo, nem dinheiro.
Assim, nos resta amostrar aquilo que é possível e inferir os valores das partes não amostradas por interpolação. E aqui a coisa começa a ficar interessante, pois existem vários métodos, apropriados para vários tipos de problemas. Claro, é possível resolver esses problemas usando o QGIS, principalmente com módulos do SAGA. Vou dar o ponta-pé inicial nesse assunto falando sobre o método de triangulação.
Um fenômeno
Antes de falar sobre o método de triangulação, vou propor um problema. Imagine que existe em uma região um dado fenômeno espacial que pode ser medido em termos quantitativos, por coletas de campo. Se não conseguiu imaginar, eu ajudo aqui, mostrando uma imagem dele:
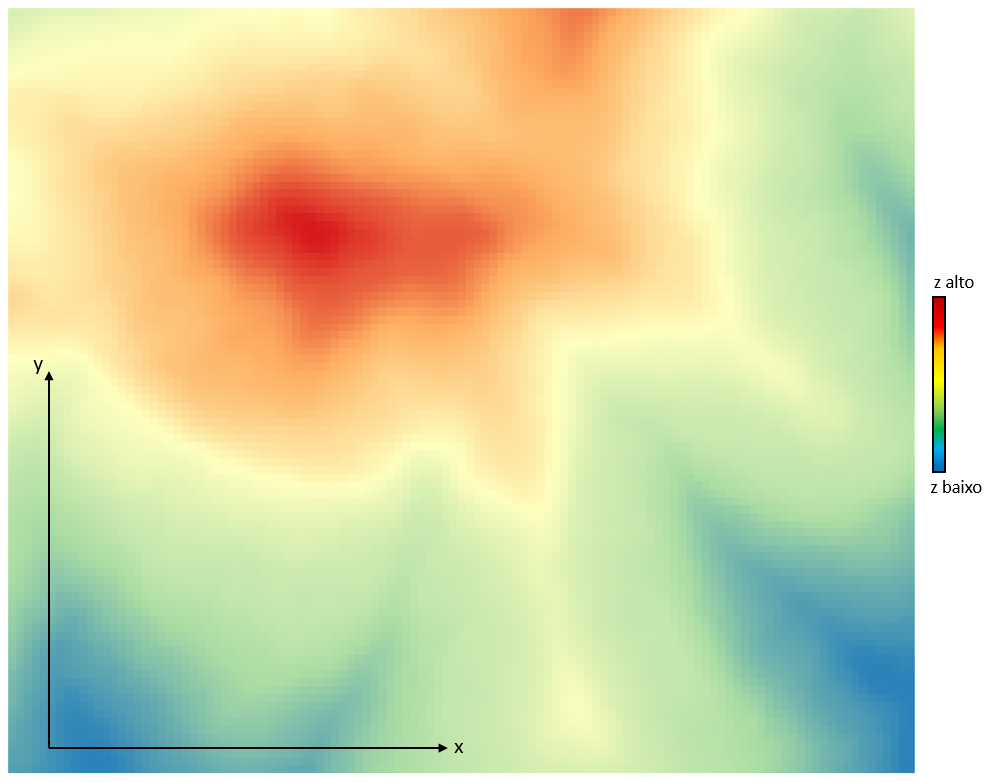
O fenômeno, que vamos chamar de “z”, pode ser qualquer coisa espacialmente distribuída: média de chuva anual, concentração de constituintes químicos na água subterrânea, teor de minério nas rochas ou mesmo a nossa velha amiga cota altimétrica, usada nos Modelos Digitais de Elevação.
Agora imagine que uma equipe de profissionais precisa mapear esse fenômeno. E eles não sabem previamente como o fenômeno se manifesta. Como eles vão proceder? (vamos ignorar a possibilidade de sensoriamento remoto aqui, ok?)
Uma opção é: (1) conseguir muito dinheiro e (2) fazer uma amostragem sistemática e extensiva, usando uma grade regular e densa.
Outra opção é (1) agir economicamente e (2) fazer uma amostragem irregular e esparsa, proporcional aos recursos disponíveis para tanto.
Ambas as opções envolvem amostragem. A diferença entre elas é a quantidade de amostras, sendo a primeira a “ideal” e a segunda a mais “realista”. O problema é: o quanto a abordagem “ideal” é melhor que abordagens realistas, que possuem menos amostras?
Interpolação por triangulação
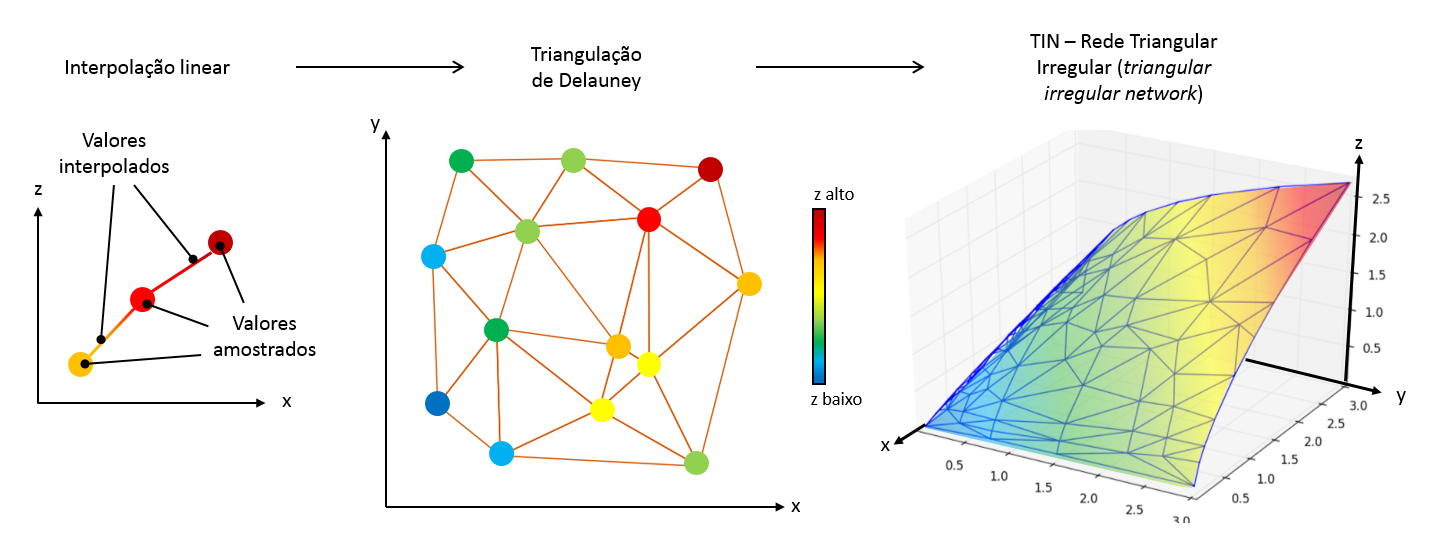
Esse método basicamente assume que o valor quantitativo do fenômeno espacial (valor de “z”) varia linearmente entre os pontos amostrados. É isso.
Essa premissa, aliada à Primeira Lei da Geografia, nos força (matematicamente) a desenhar uma malha entre os pontos, que vai apresentar sempre um padrão de triângulos – a triangulação de Delauney. Se você visualizar a malha em três dimensões, irá ver uma superfície formada por inúmeras facetas planas triangulares (o TIN – triangular irregular network). O valor de z, assim, pode ser inferido tanto na malha quanto nos planos formados.
No QGIS, um módulo do SAGA converte os valores inferidos em uma camada raster. O módulo está em: SAGA >> Raster Creation Tools >> Triangulation. Nem sequer vemos o tal do TIN: só é preciso fornecer um shapefile com os pontos. Claro, também é preciso informar qual o atributo do shapefile a ser usado como “z” e a resolução espacial da camada raster de saída. (se você quiser ver a malha triangular, existe um módulo que faz isso: QGIS >> Vector Geometry Tools >> Delauney Triangulation – o resultado é um shapefile de polígono).
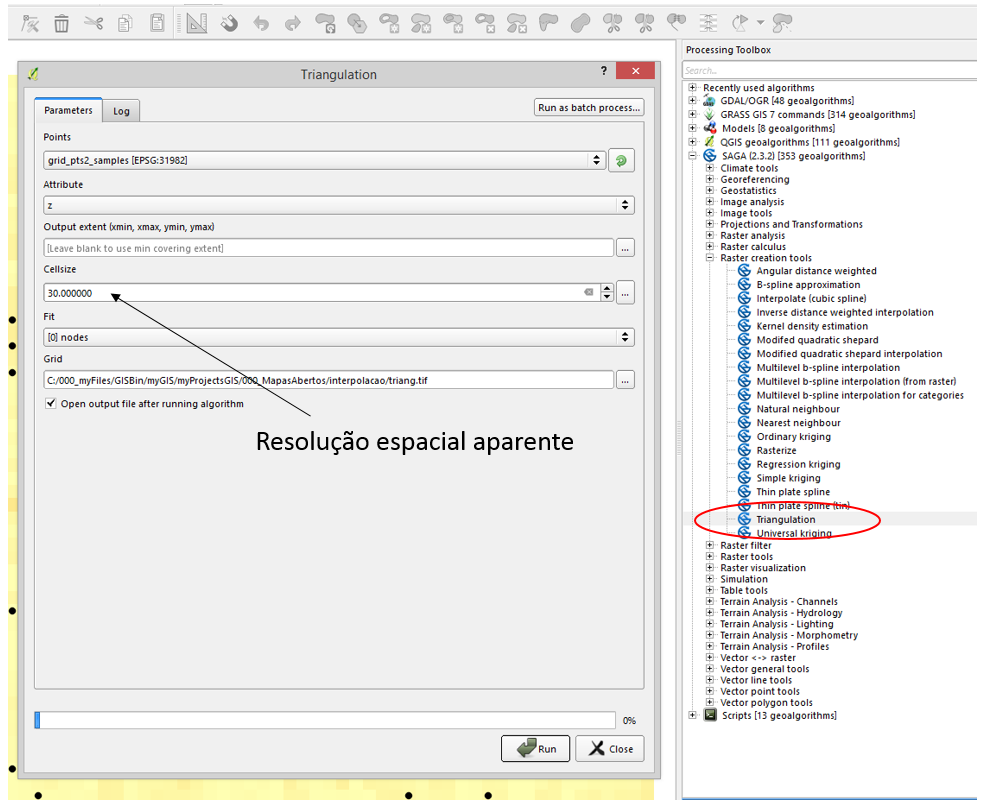
Você certamente irá sentir a tentação de produzir camadas raster impressionantes, de alta resolução, com píxeis minúsculos. Mas isso será uma resolução aparente, não real. Sim, interpolação é uma forma de mentira, mas devemos cuidar para não exagerar na extrapolação entre os pontos amostrais. A resolução real da camada será a resolução espacial da nossa amostragem, dos pontos. Eu avalio a resolução aparente de forma que a interpolação calcule o valor de 4 a 6 píxeis entre os pontos, em média.
Agora que já sabemos como a triagulação funciona e como executar ela no QGIS, podemos voltar ao problema.
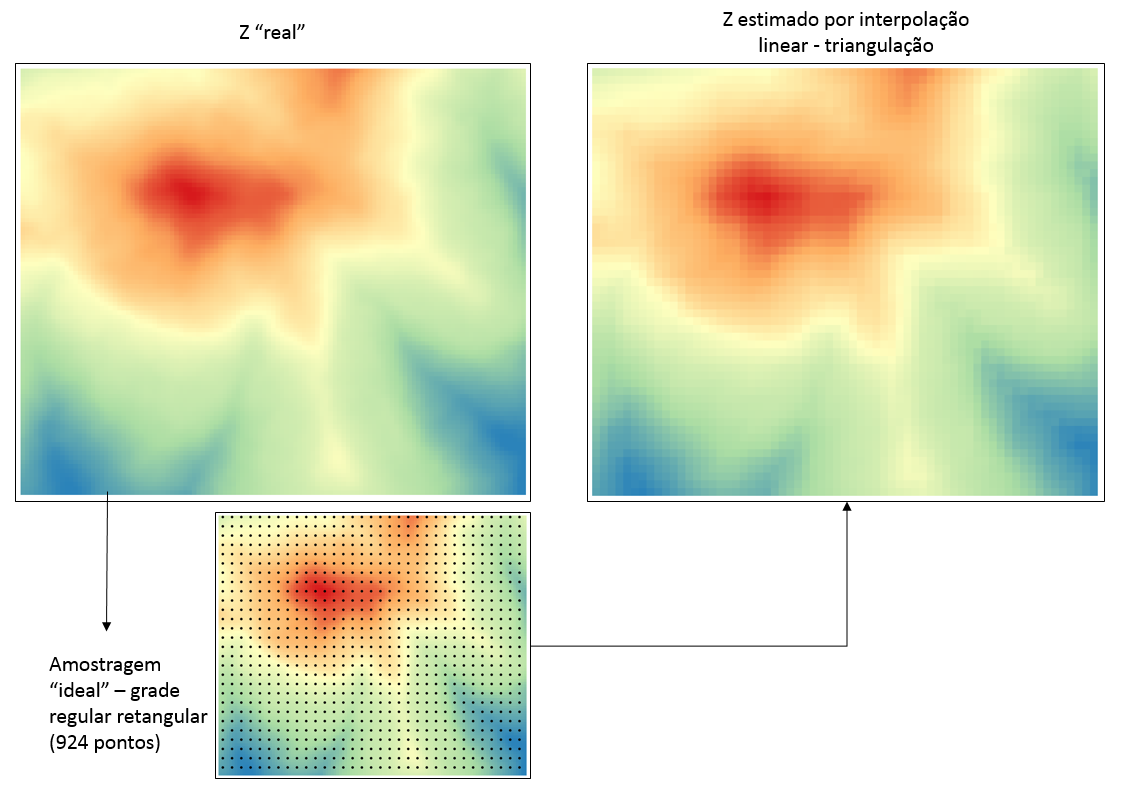
Triangulação com amostragem ideal
A amostragem “ideal” consiste em uma grade regular retangular de pontos amostrais. É possível gerar o shapefile de pontos amostrais no QGIS (em Vector creation tools >> Regular points) ou usar complementos que fazer essas coisas (como o MMQGIS). Para simular a “amostragem de campo” que a nossa equipe hipotética faria, usei a ferramenta do SAGA “Add raster values to points” (em SAGA >> Vector <-> Raster). Essa operação literalmente amostra o valor de píxel que os pontos estão imediatamente sobre. Assim, o novo shapefile de pontos criado tem um atributo de armazena o valor de “z”.
O espaçamento usado entre os pontos amostrais foi de 100 metros, resultando em 924 pontos. Assim, a interpolação por triangulação pode apresentar uma resolução um pouco superior. Defini em 50 metros. O resultado não foi nada mal!
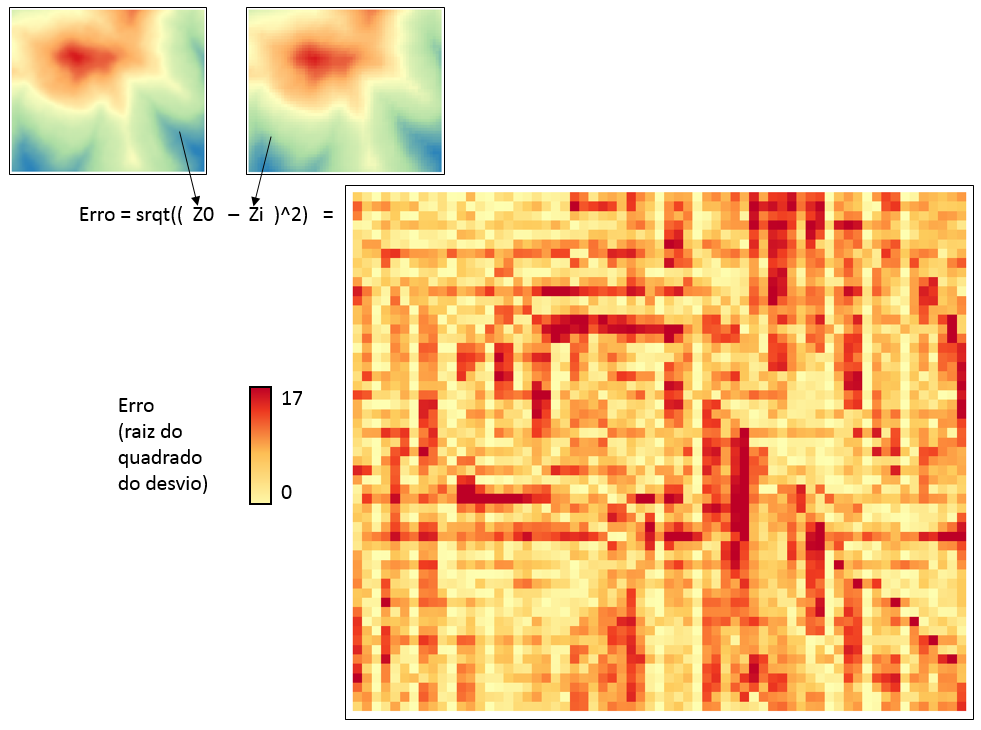
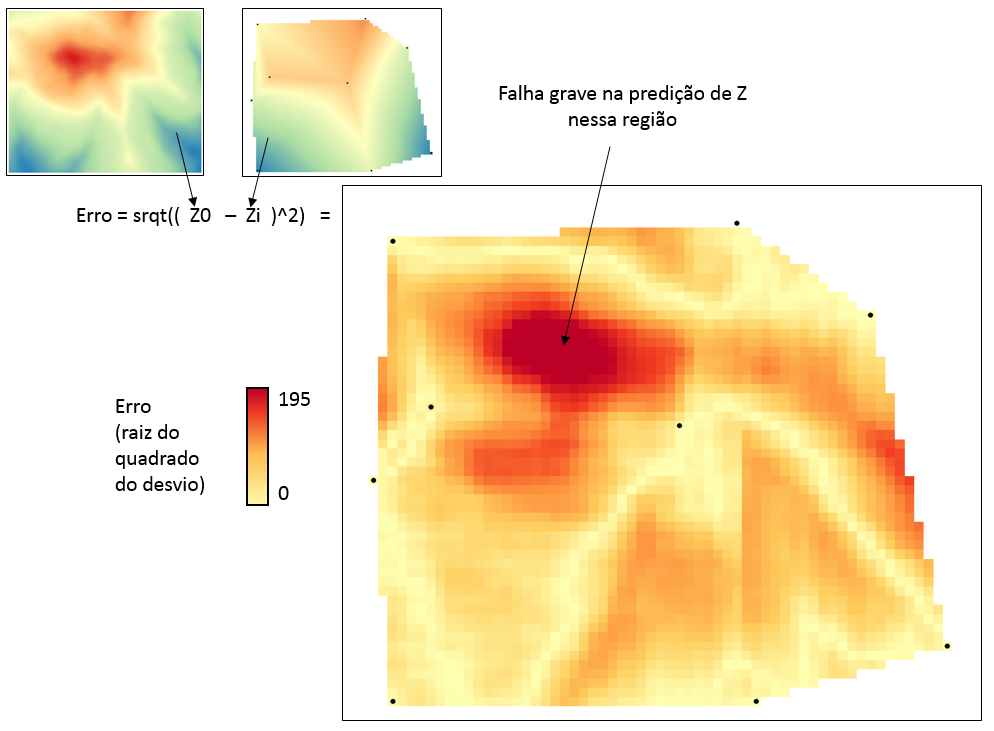
O “erro” da interpolação derivada da amostragem feita pela equipe pode ser medido, já que nós conhecemos o mapa “real” do fenômeno, isto é, os valores de z em qualquer parte. Esse erro pode ser definido pelo valor absoluto da diferença entre o valor de z interpolado e o valor “real” de z. Uma forma de achar esse valor, pela calculadora raster, é obter a raiz quadrada do quadrado da diferença entre as duas camadas:
srqt((“zi@1” – “z0@1”) ^ 2)
Onde “zi@1” é a camada raster da interpolação e “z0@1” é a camada raster “real”.
Nessa condição de amostragem ideal, o valor médio do erro foi de aproximadamente 4.5.
Amostragem realista: 20% do ideal
Para simular uma amostragem mais “realista”, removi aleatoriamente 80% dos pontos da grade regular ideal, ficando com 20% dos pontos. Percebe-se nitidamente que o retrato da realidade feito pela amostragem começa a ficar distorcido.
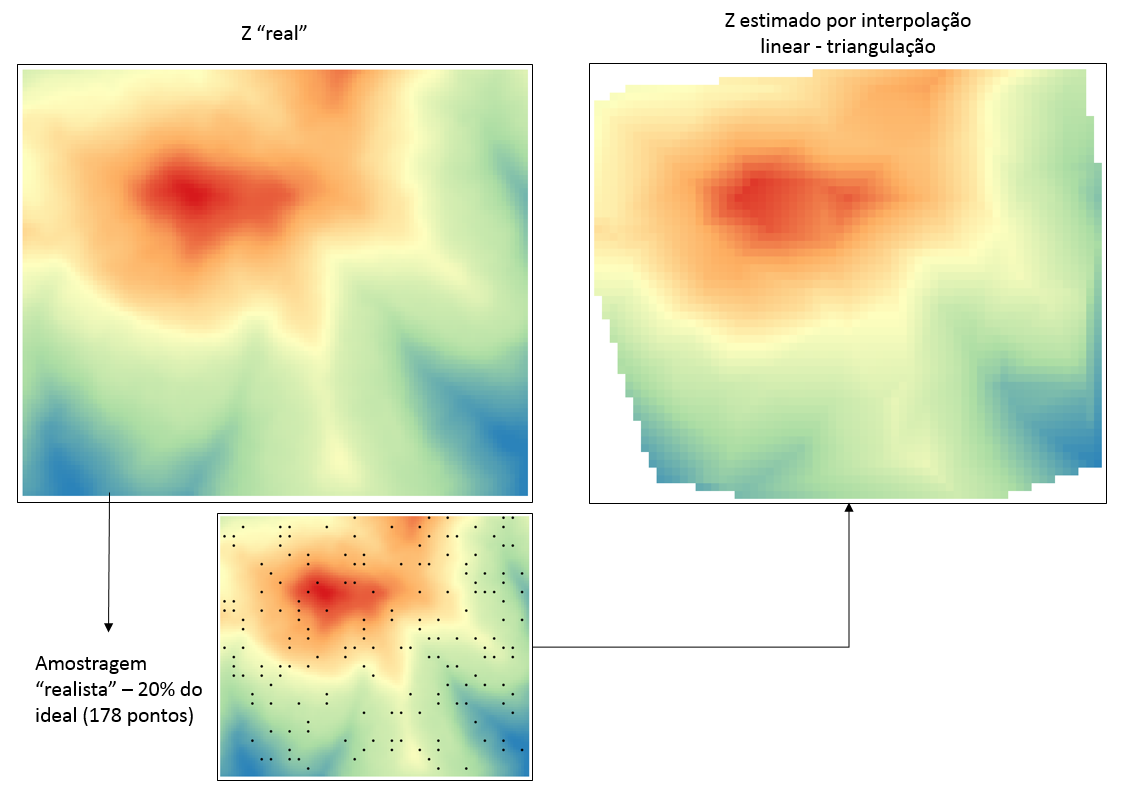
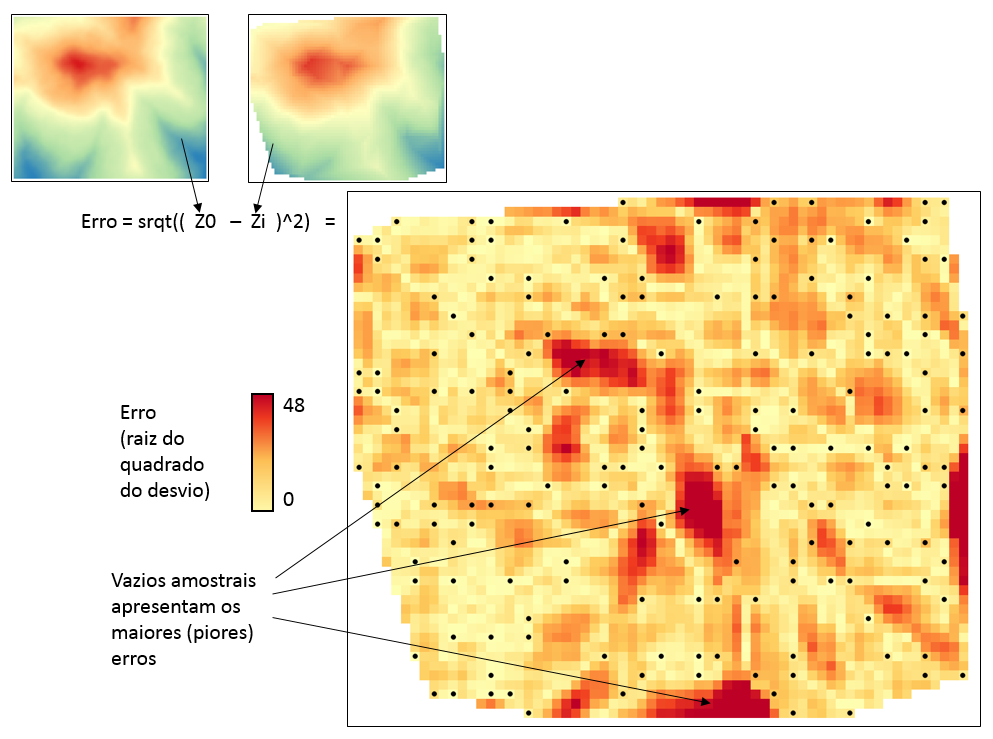
A análise do erro nos aponta uma piora: o valor do erro médio foi de aproximadamente 12, quase 3 vezes maior que na amostragem ideal. A distribuição espacial do erro demonstra claramente que os “vazios” amostrais são os focos onde o erro dispara.
Amostragem hiperrealista: 1% do ideal
São tempos de crise. Com 1% do ideal nossa equipe hipotética tem apenas 9 pontos amostrais. Será eles conseguirão fazer um bom retrato da realidade?
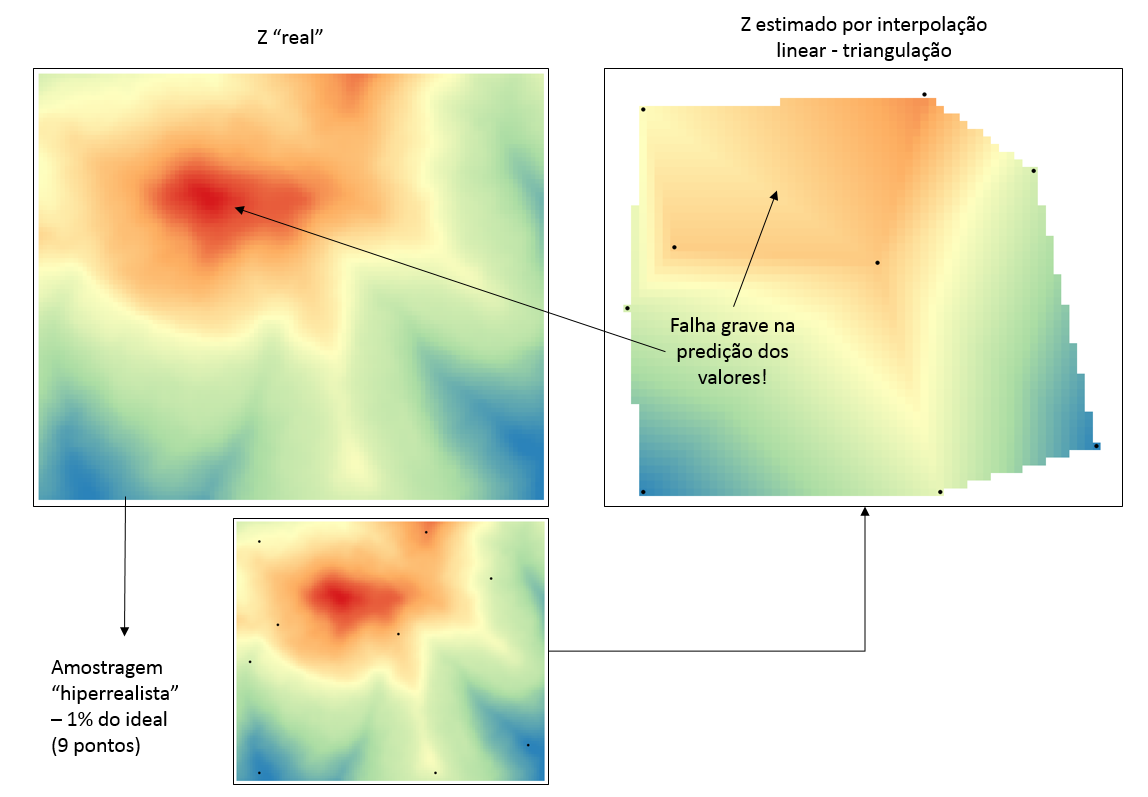
Visualmente ficou péssimo. O erro nem se fala: valor de médio de 52, 11 vezes maior (e pior) que a amostragem “ideal”. Podemos perceber que a ausência de pontos amostrais na região de valores altos de z (a “montanha” vermelha) comprometeu seriamente a predição dos valores de z nessa região.
Piora (e melhora) não-linear
Conforme reduzimos o número de pontos amostrais, o erro aumenta e o resultado piora. Mas isso não acontence linearmente. Fiz outra análise com 50% de pontos e plotei o erro médio em função do % de pontos em relação ao ideal. A função “erro” é claramente uma função “inversamente proporcial”, do tipo potência.
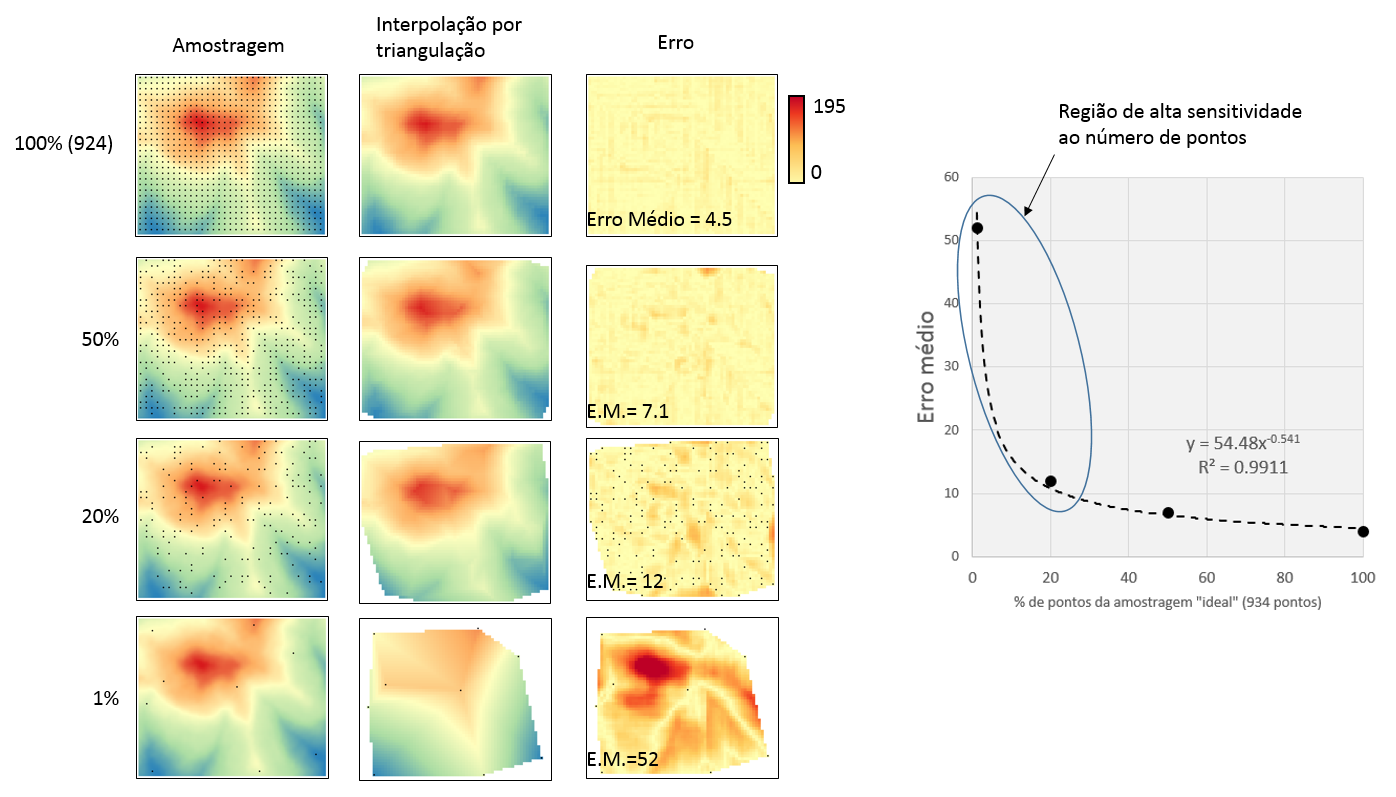
Isso é uma boa notícia, no fim das contas. Significa que se você tem poucos pontos, qualquer ponto amostral incremental trará um enorme benefício na redução do erro. O erro tem alta sensitividade nessa região. E se você já tem bastante pontos, fique de boas, pois pontos adicionais não vão fazer muita diferença.

1 comentário